深度学习初窥
by yaobin.wen
今天我听了一堂关于深度学习(Deep Learning)的入门讲座,是来自Google Research的研发工程师阮巨城老师讲的。这里我把听到的东西做一个大体上的总结。
机器学习和深度学习是什么关系? 这是去年12月初张晶姐问我的一个问题,当时我在网上稍微了解了一下之后给出的回复是:
是包含与被包含、或者说是全集和子集的关系。机器学习指的通过使用某种算法、技术来训练机器完成某种特定的任务(比如识别人脸),使机器体现出和人类一样的智能水平。深度学习是用于训练机器的某种特定的算法或技术(也就是说实现机器学习也可以使用其它非深度学习的技术,不过目前深度学习是最火的)。深度学习使用的方法大致上是神经网络技术,具体是指用计算机模拟人脑。不过,人脑中任意两个神经元之间都是可以建立连接的,所以整个大脑可以组成一张极其庞大的网,彼此之间没有明确的层次关系,但是在深度学习算法中,用于模拟人脑的神经网络其实是分层的(当然每个层次内部的模拟神经元之间会建立复杂的联系,但是层和层之间的联系要相对简单很多)。输入的数据首先经过第一层神经网络的处理,然后把中间结果传递到下一层,然后再下一层,直到产生最终结果。由于在深度学习这种技术中使用的神经网络的层次非常多,很“深”,所以称之为“深度学习”。
今天听了讲座之后,我发现上面给出的回复基本正确,但有一些地方需要修正:
- 在深度学习网络中,用于模拟人脑神经元的neuron的确是分层的,但是每一层内的neuron之间并没有联系。相反,层和层之间的neuron很可能有很复杂的联系。比如第1层有m个neuron,第2层有n个neuron,那么两层之间的联系(connection)数量很可能是m*n个。
- 深度学习网络的层次一般没有那么多,并没有真得那么“深”。
深度学习是一种模拟人脑运作的方法。人脑的基本组成单元是“神经元(neuron)”,不同的神经元之间建立起“连接(connection)”,最终所有神经元和所有的连接构建成一张巨大的“网络(network)”,所以深度学习也采用了类似的构建方式。在一篇SlideShare的PPT《[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習》中,作者李宏毅博士给出了下面的定义(如无特别说明,截图均来自李博士的SlideShare PPT):
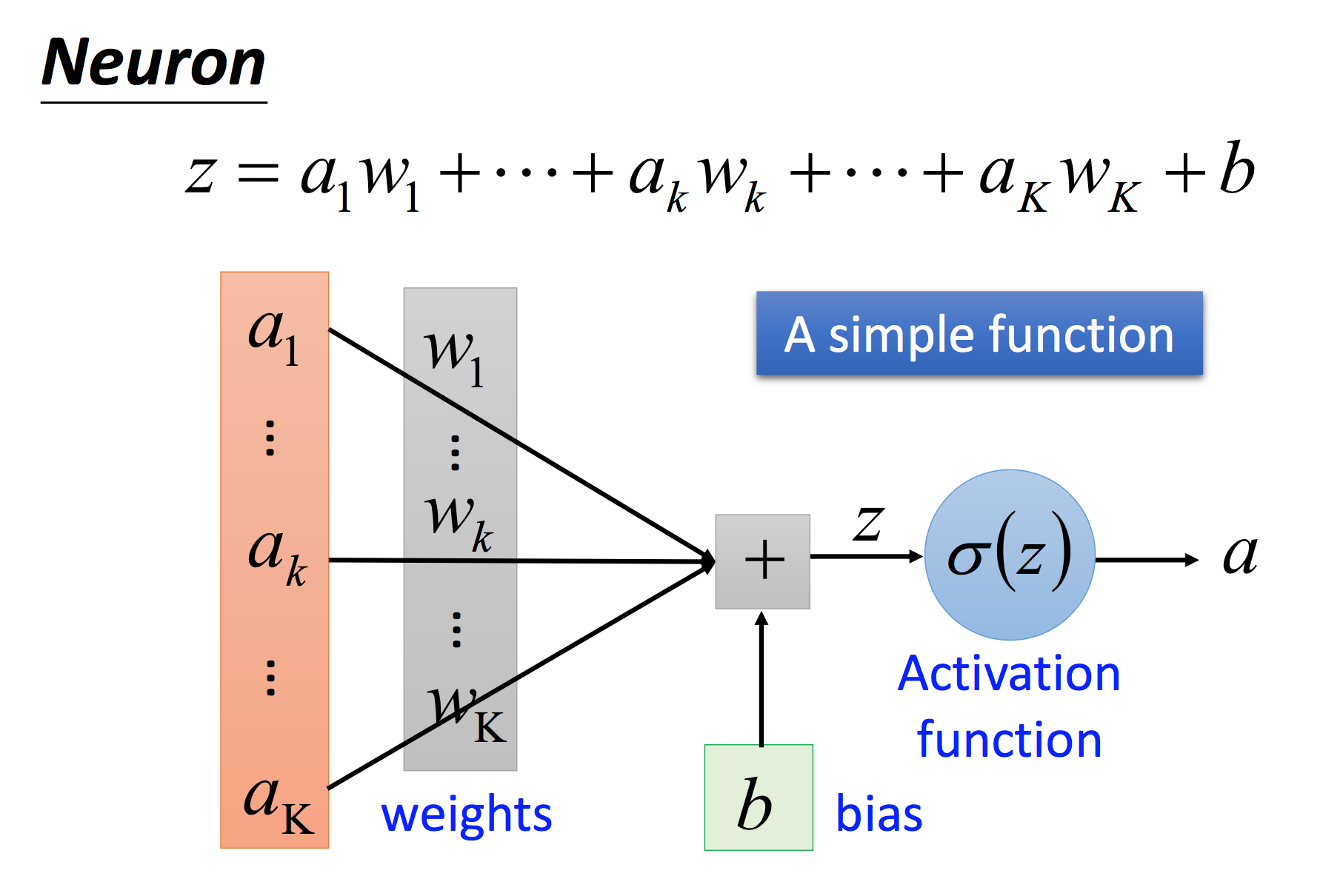
a代表的是输入信息(input),也可以称之为特征(feature)。w代表的是该特征对激发该神经元所起的作用的权重(weight),也就是说,权重越大,该特征在判断是否要激活该神经元的过程中起到的作用越大。z是在考虑到所有输入之后的最终结果。函数西格玛是用于将结果z映射到一个合适的统一值域上的函数,例如Sigmoid函数可以映射到(0, 1),最终根据西格玛函数的结果判定是否要激活该神经元。被激活的神经元会进一步导致信息的下一层传导,最终形成整个网络中信息的传递(不过下图似乎显示无论西格玛函数的值是多少,该值都会传递到下一层网络中):
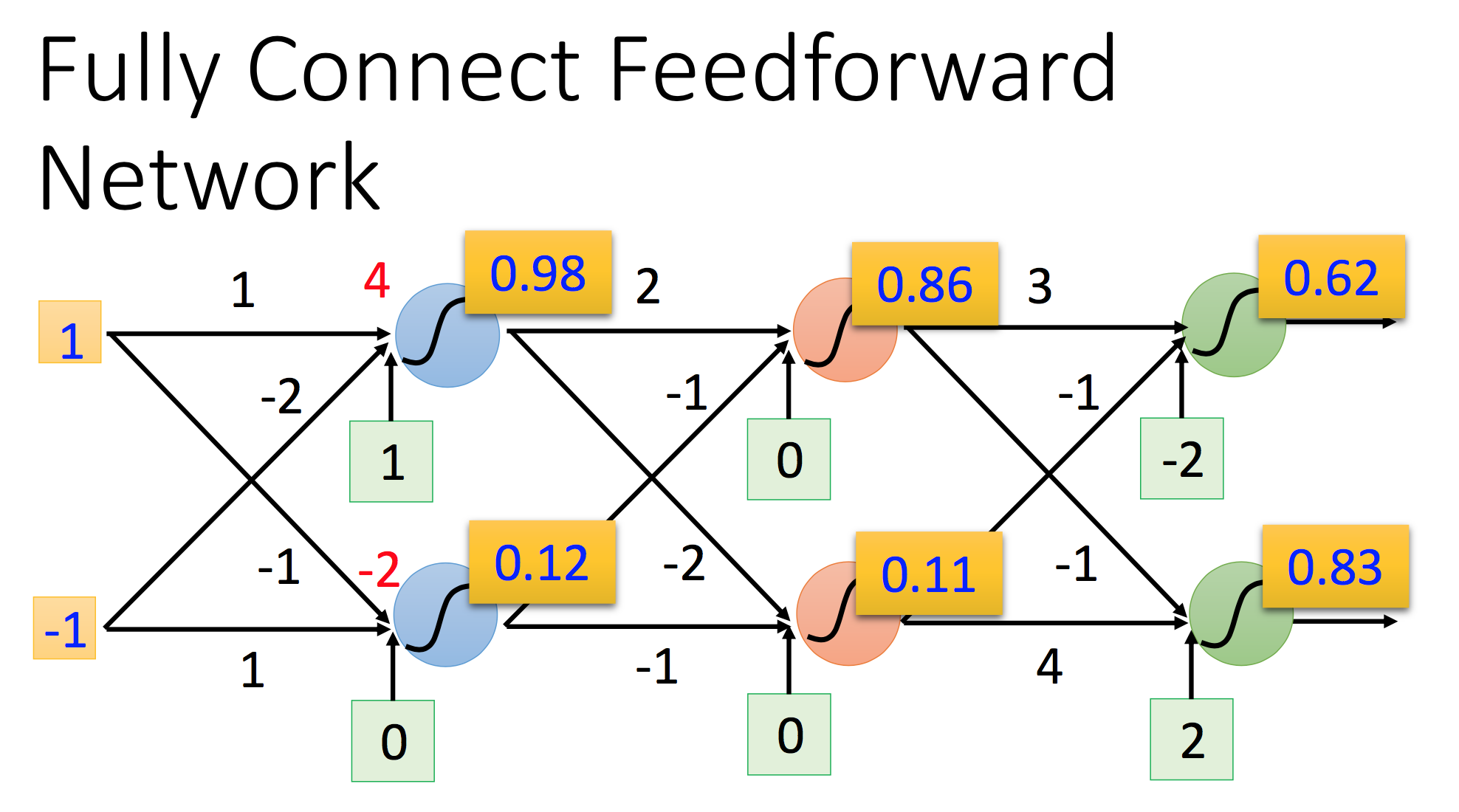
而权重值的确定,是调试深度学习网络中很重要的一环。
深度学习的整体流程可以分为两个部分:
- 正向:由输入到输出,基于现有的模型和知识做预测;
- 反向:由输出到输入,本质上就是反馈,即根据正确的结果和预测结果之间的差异来调整参数,从而改进网络。
深度学习的建模非常重要,因为如果模型不好,那么很可能看似优质的数据产出的仍然是垃圾的结果,例如在overfitting的情形下,模型对训练数据的适应性非常好,但是一旦输入更多的真实数据,则得到的结果可能非常不好,而没有经验的人根本不知道该如何改进模型。这个让我感觉更像是一个数学建模能力的问题。
阮老师在讲座中还提到了数据的预处理。他提到数据可以分成两大类:categorical和ordinal,即非数值化的、没有先后顺序的数据(例如血型),和数值化的、可以排出先后顺序的数据(例如气温),这个方面的东西在Analysis of Software Artifacts课程上讲过。这里的重点是:对categorical数据的建模要非常小心,不能随意引入可排序的性质,不然机器可能会对数据产生不可预期的理解,导致结果的完全错误。
我们还需要设定loss function,用于评估模型的错误率。我们的目标是要最小化loss。
阮老师还讲了很多内容,但很多都是比较细的细节,我这里没办法一一总结。更多的可以参考李博士的PPT。
我自己的一些想法:
- 虽然深度学习模拟的是人脑,但是似乎还模拟的不够,一个方面就是:神经元之间的连接是要事先建立好的,即网络的结构是要事先设定好的。但是真实的人脑的神经元之间的连接是可以后天慢慢建立的,即“神经网络可以不断生长”。这似乎是人脑越用越聪明的根本原因。不过我需要查更多的资料才能确定这个说法是否靠谱。
- 机器用于学习的模型似乎还是需要人工来调整。是否可以让机器自己不断调整模型?注意我说的不是调整模型中的参数(参数的调整可以在反馈流程中自动完成),但模型的自动演化不知道现在有没有方案。或许我应该搜索一下”deep learning model autonomous evolution”之类的关键字。
- 深度学习本身只是一门技术,还是需要和具体的问题相结合才能对人类产生价值。我目前比较关心的方向有工作效率的提升问题;韦思泰和关心的问题是能源管理;MVS关心的问题是SLAM。深度学习是否可以在这些领域发挥功能?另外,一些热门的技术(比如区块链)是否可以和深度学习产生联系?
最后是一些关于机器学习/深度学习的参考资料:
- Deep Learning:一个汇集了非常多的关于深度学习资料的网站。
- An absolute beginner’s guide to machine learning, deep learning, and AI
- 在Google上搜索”deep learning energy management”这个关键词,可以找到一些在能源管理上应用深度学习的资料。